ABC276後記 (A~F)
A - Rightmost
問題概要
与えられる文字列で一番最後の
aは何番目か
解法
まずは答えansを初期値-1として持っておき、を先頭から見ていく。
aが登場するたびにansを更新していけば良い。
提出
B - Adjacency List
問題概要
頂点
辺の無向グラフが与えられる。
それぞれの頂点について、その頂点と直接つながっている頂点を昇順に出力せよ
解法
グラフの基礎的な問題。グラフを隣接リスト表現(≠隣接行列表現)で表してあげる。
提出
C - Previous Permutation
問題概要
順列の辞書順で一つ前の順列を出力せよ
解法
C++だとSTLで一発。std::prev_permutation()を使う。
僕の解法はそれぞれをから引いて、
std::next_permutation()を使っている
提出
D - Divide by 2 or 3
問題概要
与えられた数列に対して、
- 2の倍数であるような数
を2で割る
- 3の倍数であるような数
を任意の回数行なって全ての数を同じにする時、最低で何回必要か(不可能なら-1)
解法
全て同じにできる場合、その数は数列の最大公約数となる(すべてがその数を因数として持つから)。したがってまずは数列を最大公約数で割ってあげる。
次にそれぞれが2,3でそれぞれ何回割れるかを考える。これはwhile文を回してあげればいい。もし2と3で割れるだけ割った後、1になっていなければ、数列をすべて同じ値にすることは不可能。
提出
E - Round Trip
問題概要
スタート地点、道、障害物からなるのグリッドが与えられる。この時、スタートから出発してスタートへ戻ってくる道順であって、同じ道を2回以上通らないものは存在するか
解法
DFSを行う。
スタート地点から初めて、来た道を戻る以外の方法(深さの差が2以上)でスタート地点へ戻ることができた場合、それまで探索した経路が目的の経路となる
提出
F - Double Chance
問題概要
枚のカードがあり、
番目のカードには
と書かれている。このとき、
枚目までのカードから、一枚カードを引いて元に戻す操作を2回行うときの、その2枚のうち大きい方の数値の期待値
を全てのについて求めよ
解法
カードを引く順番まで区別すると、ありうる引き方は全て等確率で起こる。したがって、とりうる最大値の総和を求め、最後にで割ってあげれば良い。
ここで、
の時にとりうる最大値の総和
は、
番目のカードを使う時に取りうる最大値の総和
となる。そして、 番目のカードを使う時に取りうる最大値は、
- 他方のカードの数字
が
以下の場合、
- 他方のカードの数字
- 同じカードを引いた場合、
となって、それぞれの場合の総和が求まれば良い。 1、2の場合は、BITやセグ木を使ってあげることで、
- 1の場合:
- 2の場合:
を高速に求めることができる。また、1,2の場合は番目のカードを先に引くか後に引くかの2通りあるため、2倍する。
提出
ARC143 B - Counting Grids 解説
問題
のマス目の各マスに 1 から
までの整数を 1 つずつ書き込む方法であって, どのマスも以下の条件のうち少なくとも一方を満たすようなものの個数を 998244353 で割ったあまりを求めてください.
- そのマスに書かれている数より大きい数が書かれているマスが同じ列に存在する.
- そのマスに書かれている数より小さい数が書かれているマスが同じ行に存在する.
解法
まず問題から、数学で解くか、剰余を取れと言われているのでDPで解くと検討をつける。まずは数学で考察してみよう。
シンプルに考えると数え上げの雰囲気だが、そのまま数え上げようとしても剰余を取らせる以上愚直は無理、かといって効率のいい数え上げ方法も見つかりづらい。
ここで、条件を見てみると、「AまたはB」の形になっている。このタイプの数え上げは余事象(AでなくBでもない)を考えるといいと相場がきまっている。考察してみよう。
すると、「条件を満たさない盤面の中で、条件を満たさないマスは高々1つ」と仮定すると、余事象の数え上げは、そのマスに書かれた数から以下のようにして簡単にできそう
- 同じ列:
より小さい数
個から
個選んで並べる
- 同じ行:
個から
この部分がで、
を全探索するとき、全体で計算量は
で十分高速。あとは、それぞれに(または探索後の合計値に)残った
個のマスに余った数を適当に並べる場合の数をかけてあげれば余事象の数え上げは完了。
ただ、これで終わりではない(いいけど)。仮定の証明が必要だ。今回、
「条件を満たさない盤面の中で、条件を満たさないマスは高々1つ」
という仮定があるので、これを考察してみる。
まず、条件を満たさないマスともう一つのマス
について、
としてみる。
このとき、Yと同じ列で、Xと同じ行にあるマスは Xより大きいので当然Yよりも大きい。となるととなるYは全て条件を満たす。
同様に、についても同じように考えると、これも条件を満たす。
以上から、条件を満たさないマスは高々1つということがわかったので、ここまでの解法が合っていることがわかった。
実装
int main(){ ll n; cin >> n; modint<998244353>ans = 1; // 答え modint<998244353>no = 0; // 余事象 modint<998244353>offset = 1; // 残りのマスの並び替え rep(i, n*n-2*n+1) { offset *= i + 1; } rep (i, n*n) { ans *= i + 1; modint<998244353>cnt = 1; rep(j, n-1) { cnt *= i-j; // Xより小さい数の順列 cnt *= (n*n-i-1)-j; // Xより大きい数の順列 } no += cnt * n * n * offset; // 数え上げ*場所*残り } cout << (ans - no).value() << endl; }
ABC257後記(A~E)
A - A to Z String 2
問題概要
A,B,C...がN個連続されて作られる文字列のM番目を出力してください。
解法
制約がと小さいので作っちゃうのが簡単そう
提出
B - 1D Pawn
問題概要
N個のマスとK個の駒がある。Q回駒に対して、「端か隣に駒がなければ右に動かす」という操作を行ったあとの各駒の場所を出力してください
解法
問題だけをみると、右端かどうかと、隣にコマがあるかどうかでややこしそう(このままやっちゃうのもアリ)。
ただ、マスN+1に駒を置いてしまえば、処理は「隣に駒があるかどうか」で済む。
提出
C - Robot Takahashi
問題概要
体重で大人と子供を判断したい。ボーダーXを適切に決めてXとの上下で判断するとき、最大で何人正しく識別できるか
解法
まず、この問題で与えられる数の順番は変えても問題ないので、体重でソートしてみる。
そうすると、高橋ロボは決めた基準より左側は子供、右側は大人と判断することがわかる(つまり、iとi+1の間をボーダーに決めたとき、[1,i]は子供、[i+1,n]は大人)。あとは、どこをボーダーにするかを全探索して、それぞれについて右側、左側それぞれで正しく判断できている数を数えてあげれば良い。この部分は累積和を使ってあげれば高速に判定できる。
(ソート後の)i番目とi+1番目の体重が同じの場合は、そこはボーダーにできないことに注意
提出
D - Jumping Takahashi 2
問題概要
各ジャンプ台の数値と高橋君のジャンプ力S(=訓練回数)で、マンハッタン距離が
までの場所にジャンプできるジャンプ台がいくつかあるとき、ある1点からどのジャンプ台にも何回かのジャンプで到達可能になるための訓練回数の最小値を出力してください。
解法
まず注目するのは制約でとなっていること。ここから、ジャンプ台の数に依存した解法が良さそうと見当をつけて考察。
そして、求めるものは訓練回数の最小値なので、二分探索ができないか考える。(無理そうならDPを覚悟)
二分探索となると、訓練回数に対して十分に高速な判定方法を考えることになる。ここで、Nが小さいので最初は愚直解を考えてみよう。
問題によると、訓練回数の条件は、「あるジャンプ台を始点として、そこから0個以上のジャンプ台を経由してどのジャンプ台にも到達できる」とのこと。ということは、愚直解は
- 始点は全探索
- 到達可能かはグラフ探索
で、この二つを組み合わせることになる。
ここで計算量を見積もると、始点探索が
、グラフ走査が
(頂点
個、辺が
本)だから、
で、この問題だと十分に高速だとわかるので、これで実装を進める。
二分探索の上限値は要注意(大きいとオーバーフローする)
提出
E - Addition and Multiplication 2
問題概要
1桁の整数iを買うのに円かかるとき、N円以下で作れる最大の数を出力してください。
解法
1. 入力の加工
まずは最終的な数は置いといて、与えられるCを「大きい数ほどコストがかかる」ように最適化したい。見てみると、
i<jかつのとき、整数iは使わない。(iの代わりにjを使った方がいい)
となることがわかる。さらに考察すると、
末項がの最長増加部分列を取り出す
という操作をすればいい。実装的には、「末尾から、『それまでの最小値>現在の値』となった値を取り出す」ことをする。
2. 問題の考察
では本題に入っていこう。制約と入出力例2を見る限り、DPなど値を保持しながらの解法は厳しそう。ここで、整数を買う順番を入れ替えても総出費は変わらないことが自明なので、問題のは無視して良さそう(後で並び替えればいい)。そうなると、答えとして保持するのは「整数iを何個買うか」を保持した配列で十分で、出力するときは配列の各値から大きい順に出力すれば良い。
ここまで、答えをどう生成するかがわかったので、次は「どの数をどれだけ買うか」を考える。
ここで、数字の大小を決定するのは、
- 桁数
- (桁数が同じの場合)桁を上から見た時の各桁の大小
なので、まずはたくさん買うことから始めると良さそう。
(ここからは議論簡略化のため、1.の処理の後1から9全ての整数が使えるとする。)
とはいえ、いくら桁数の多い11111...でも91111...には勝てない。つまり、最初の「桁数が最大のケース」から始めて、最終的には「桁数は変えないままなるべく大きい数を買うケース」に移行させたい。
ここで、91111...が作れる状況で81111...を作ること、一般化すると「ある数Nより大きい数が買える状況でNを買う」という操作は自明に愚行なので、これは貪欲に大きい数から買っていけばいい。
実装は、
- まずは一番小さい(=コストが安い)数aで埋めて桁数を決定
- 処理1で決めた使う数の中で、大きい数から順にaを変えられるだけその数に置き換える
を繰り返していけばいい。
(提出例だと一番最初に「使う数」として整数0コスト0を追加して、実装を楽にしている)
あとは提出で理解してほしい
提出
ABC256後記(A~E)
A - 2N
問題概要
2Nを答えてください
解法
2Nを出力すればいい。これはpow(2,n)や(1<<n)でできる
提出 atcoder.jp
B - Batters
問題概要
長さNの数列Aがあって、以下の操作をN回繰り返すとき、4マス以上進む駒の数を答えてください
- マス0にコマを置く
- すべての駒を
だけ進める
解法
N個の駒は、
- 1個目:
- 2個目:
- 3個目:
...
のように動く。このとき、i番目の駒は必ずi+1番目の駒より前にいるから、「4マス以上進むものの中で一番後ろのもの」が分かれば良さそう(その駒よりも先に置かれた駒はすべて4マス以上進む)。
では、どうやってそれを見つけるか。
これは単純に、一番最後の状態を考えて、4以上になるまでから逆順に足していけばいい。
提出 atcoder.jp
C - Filling 3x3 array
問題概要
縦横それぞれの合計が与えられるので、それを満たす3x3のグリッドの個数を求めてください。
解法
一見、すべてのマスを全探索しないといけなさそうに見える。
ところが、縦、横それぞれについて、2 つわかってしまえば残りの一つはわかる(合計から引けばいい)ので、4つだけを全探索すればいいことになる。
あとは、出る値について、
- 入力の条件を満たす
- 最小値が1以上
ことを判定すればいい。
実装は重めだけど頑張る
提出 atcoder.jp
D - Union of Interval
問題概要
与えられる区間の和をとってください
解法
ここで、問題をちょっと読み替えてみると、こうなる。
これができれば、あとはimos法で各場所のブロック数を求めてあげて、ブロック数が1以上の区間を列挙すればいいということがすぐにわかる。
imos法:区間[l,r)に対して、imos[l]に1加算、imos[r]に1減算して、最後に全体で累積和をとる手法
提出
E - Takahashi's Anguish
問題概要
君は
君が嫌いで、i君よりも先に
君にキャンディが渡されると
だけ不満になる。
このとき、不満の合計の最小値はいくらか。
解法
一見複雑そうだが、人間関係は結局(有向)グラフなので、グラフにしてみる。こんな感じで有効辺を張ってみる
AはBが嫌い=AからBにコストCの辺
こうみると、グラフになるべく沿って進めば良さそう。
とすると、考えるのは「0本以上の辺を消してトポロジカルソート可能にする時、削除する辺のコストの合計の最小値」となる(削除した辺=逆走してコストCを受け取る辺)。
つまり、そうしてできたできたトポロジ列の順に辿ってキャンディをあげればいい。
ではどの辺を消せばいいかというと、そもそもトポロジカルソート可能にするということは、ループを無くすことなので、強連結成分ごとに(ループごとに)分けて、その中で一番コストが低い1辺だけを切ってあげればいい。
ここで切った辺のコストの総計が答え
トポロジカルソート:有向グラフで、辺の向きがすべて同じになるように直線状に並び替える方法。ループがあるとできない
強連結成分分解の実装: ここを参照
提出
ABC-237 後記
はじめに
えっと....BとD、間違えないでくれません...?()
ガチ目に困惑した...
A - Not Overflow
-231≤N<231か判定するだけ
int main(){ ll n; cin >> n; if(-pow(2,31)<=n && n < pow(2,31)) cout << "Yes"; else cout << "No"; }
B - Matrix Transposition
2通りの解法がある
- 入力を普通に受け取って、行と列を入れ替えて出力
- 入力を行と列を入れ替えて受け取って、普通に出力
僕は後者で解きました
int main(){ ll h, w; cin >> h >> w; vector<vector<ll>>G(w, vector<ll>(h)); rep(i, h){ rep(j, w) cin >> G[j][i]; } for(auto i : G){ for(auto j : i) cout << j << " "; cout << endl; } }
C - kasaka
先頭にaをいくつかつけて回文にできるかどうか
まず、末尾のaをカウントしながら消していき、カウントした分だけ先頭からaを消す
そして、出来上がった文字列が回文かどうか判定する(dequeを使うと便利)
int main(){ string s; cin >> s; deque<char>c; bool ok = false; ll cnt = 0; rep(i, s.length()){ ll t = s.length()-i-1; if(s[t] != 'a' || ok) c.push_front(s[t]); else ++cnt; if(s[t] != 'a') ok = true; } rep(i, cnt){ if(c.front() == 'a') c.pop_front(); } rep(i, c.size()){ ll t = c.size()-i-1; if(c[i] != c[t]) { cout << "No"; return 0; } } cout << "Yes"; }
D(B) - LR insertion
挿入位置を移動させながら数字を入れていく
愚直にやるとO(N2)で間に合わない...
なので、文字列を逆順にしてみようと思う。
そうすると、Rの時列の最も左、Lの時列の最も右に追加すればいいことがわかる。
これを実装すればO(N)で処理可能
int main(){ ll n; cin >> n; vector<char>c(n); rep(i, n) cin >> c[i]; reverse(ALL(c)); deque<ll>que; que.push_back(n); rep(i, n){ if(c[i] == 'R') que.push_front(n-i-1); else que.push_back(n-i-1); } for(auto i : que) cout << i << " "; }
いやぁこれがB問題だったとは()
E - Skiing
今いる場所より低ければその差分だけ嬉しく、高かったらその差分の2倍悲しくなる時、達成できる嬉しさの最大値
重み付きグラフとしてみると最長経路問題を解けば良さそうということがわかる。
でも、正負の辺があるからダイクストラは使えなさそう...?
実は、そんなことない。
まず、なぜダイクストラでは負の辺がある時最短経路問題を解けないのかを考えてみよう。
これは、負の辺があると、総和が負になるサイクルができることがあり、そうなるとそこをループすればいくらでも短くできてしまうからだ。
では、今回はどうだろう。道を登る時、差分の2倍だけ悲しくなるので、ループするとどんどん悲しくなる。つまり、ループすれば嬉しくなるサイクルはないので、普通にダイクストラが使える。
大嘘。after_contestで落ちました..
最長経路問題であることに注意して実装
int main(){ ll n, m; cin >> n >> m; vector<ll>h(n); rep(i, n) cin >> h[i]; vector<vector<pair<ll,ll>>>G(n); rep(i, m){ ll a, b; cin >> a >> b; --a, --b; G[a].push_back({b, (h[a]-h[b]) * (h[a] < h[b] ? 2 : 1)}); G[b].push_back({a, (h[b]-h[a]) * (h[b] < h[a] ? 2 : 1)}); } priority_queue<pair<ll,ll>>que; vector<ll>dist(n, -INF); dist[0] = 0; que.push({0, 0}); while(!que.empty()){ auto [d, now] = que.top(); que.pop(); if(dist[now] > d) continue; for(auto [i, j] : G[now]){ if(chmax(dist[i], dist[now]+j)) que.push({dist[i], i}); } } cout << *max_element(ALL(dist)); }
F解きたかった....
入水記念記事
はじめに
どうも、Lukeです。ABC235でようやく水コーダーとなれました!!!!
競プロを真面目に始めてから2年半、かなりかかりました..><
ということで、この記事では、入水を記念して(?)競プロとかで僕がやってきたことを書こうと思います。
学んだアルゴリズム
僕はこれまで以下のようなアルゴリズムを学んできました。
ざっとこんな感じです。この中からいくつか自分の好きなアルゴリズムについて少し話そうと思います。
DFS/BFS
おなじみのグラフ探索の基本系ですね。グラフは僕にとって結構好きな分野で、グラフという多少幾何的なものをプログラムで処理して、迷路のように探索を行うの、面白くないですか?特に、この二つのアルゴリズムはデータ構造を変えるだけで違ったアルゴリズムになったり、グラフ以外にも応用できる点が好きです。
UnionFind
これ、汎用性高すぎる...
最初はグラフくらいにしか使わないだろうと思ってたのに、かな〜り広い範囲で活躍してくれます
尺取り法
これは、面白い、というよりは布教ですが...
尺取り法って、大体の人がforとwhileの二重ループで書いてますが、whileの1重ループだけでかけるよ!!!
ダブリング
これも結構好きです。なんとなく。
何をしてきたか
では次に、僕がこの2年間何をしてきたかについて話します。
一言に言ってしまえば精進と読書(笑)です。
精進は、AtCoderProblemsのRecommendationsや、茶埋め、緑埋め、BootCampを埋めていました(なおまだ終わってない)。後は典型90の★4までは埋めてます。★4までだとおよそABC-E/Fあたりの難易度までカバーできそうです。埋めておくことをお勧めします
そして読書(笑)は、おなじみの蟻本、けんちょん本、E8本の3冊です。中でも、後ろ二つは本当に読んでよかったと思います。執筆者のけんちょんさんとE869120さん、本当にありがとうございます!!!!!
ここからは、僕の競プロerとしての歩みを見ていきます。
まずはレートです
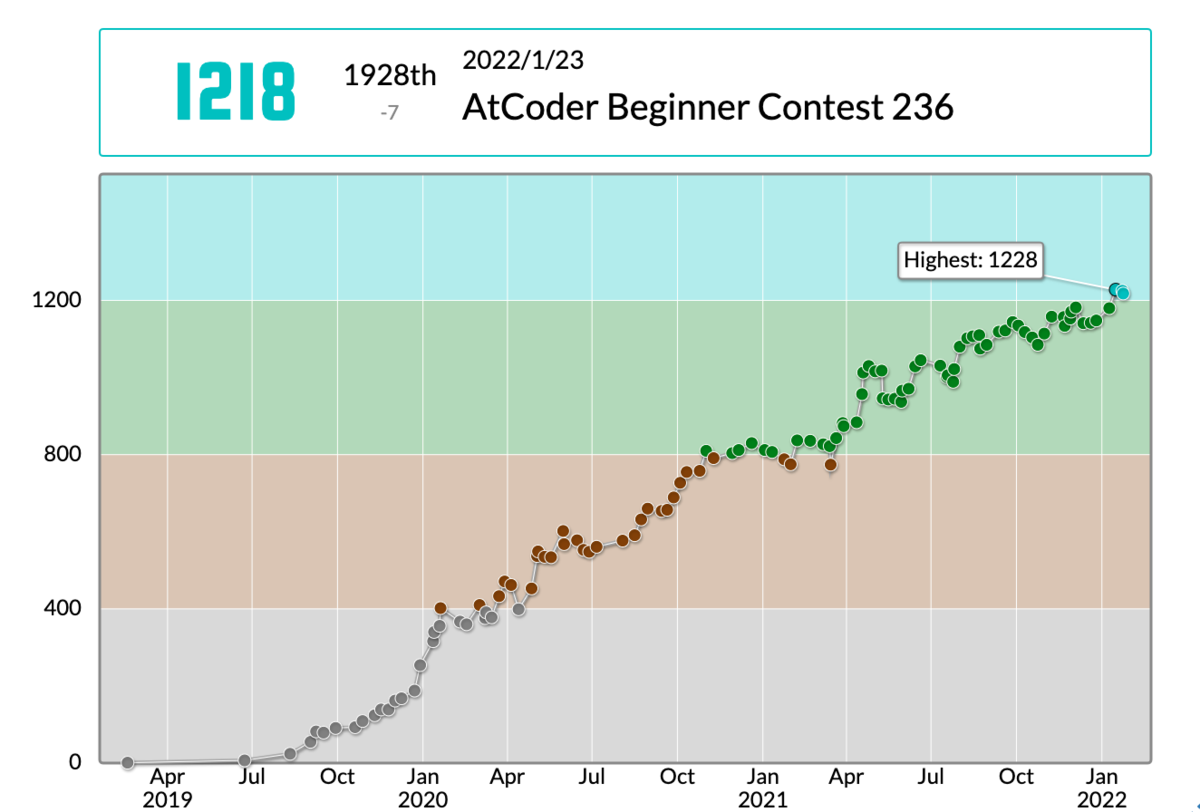 じゃんっ!ほぼ線形!()
じゃんっ!ほぼ線形!()
あまり見どころのないグラフですが、強いていうなら緑のところで一度急上昇、急降下してますね。この時は問題の相性がよかったんだと思います...(ちなみにその後萎えました)
これまでほぼ線形を保ってきてるので、伸び代は十分にあるかと!来年には入青にゃ!
ここで僕が競プロをしていく中で一番辛いことを...
同校で競プロerがほとんどいない!!!!
これ、かなり辛いです...話が通じない....
高一で競プロer見つけて嬉しかったです
さいごに
ここまで、読んでいただきありがとうございました。 正直書き足りないけど何描けばいいか分からないので、書いて欲しいことあればコメントしてください!
ちなみに、ろっかーくんは僕の彼氏です。大好きです。
ARC107 C - Shuffle Permutation
概要
与えられた行列を条件に合うように動かすとき、最終的に何通りの行列が得られるかポイント
この問題におけるポイントは、・行の操作、列の操作はそれぞれ独立で、どんなに操作しても位置関係は変わらない
ということ。
しっくり来なければ、行列のある一行(あるいは一列)に印をつけ、何回も操作を行ってみてください。どんなに操作しても印が一列になっているはずです。
例(5*5の配列)

行1と行3を入れ替え

列2と4を入れ替え

解法
このポイントがわかれば、あとは楽です方針としては、
①どの行同士が交換可能かをグラフとして保存
②できたグラフについてのすべての連結成分について、その成分の要素数の階乗をかけ合わせる(ある連結成分iの要素数がS[i]で連結成分がm個のとき、S[0]!*S[1}*...*S[m])
③①、②を列に対しても同様に行い、行での結果*列での結果が答え
(ぼくはUnionFindができないので、こうやってグラフでやっています)
コード
① どの行同士が交換可能かをグラフとして保存
vector<vector<ll>>able_swap_num_i(n,vector<ll>());//グラフ定義 rep(i,n){ //見る行 rep(x,n){ //比較対象の行 if(x==i) continue; //比較対象が自分の場合はスルー bool ok=true; //その行と交換可能か rep(y,n){//列ごとに見る if(a[i][y]+a[x][y]>k){ //条件を満たしていないので、その行とは交換できない ok=false; break; } } if(ok){ //有向グラフっぽいけど、この逆の場合(iとxが逆)もあるので無向グラフ able_swap_num_i[i].push_back(x); } } }
②できたグラフについてのすべての連結成分について、その成分の要素数の階乗をかけ合わせる
グラフ走査には、幅優先探索を使いますvector<ll>dist(n,-1); //本来は距離用だけど、今回は訪問済みかの印 ll swaps_i=1; //行について考えたときの答え rep(i,n){ //訪問済みならスルー if(dist[i]!=-1) continue; //BFSここから queue<ll>que; que.push(i); ll members=1; //連結成分内の要素数 dist[i]=0; while(!que.empty()){ ll now=que.front(); que.pop(); for(ll next:able_swap_num_i[now]){ if(dist[next]!=-1)continue; que.push(next); dist[next]=dist[now]+1; ++members; } } //階乗 rep(i,members){ swaps_i*=(i+1)%mod; swaps_i%=mod; } }
列についても同じように。
ソースコード全体
半分くらいまでは関係ないです